MySQL 查询优化 - Explain
使用 EXPLAIN 分析查询语句,解析每一项的含义,并给出优化建议。
MySQL 版本:10.5.5-MariaDB MariaDB Server。
一、EXPLAIN
查看某一查询语句的执行计划:
1 | |
得到如下执行结果:

id
含有子查询的时候,表明各语句执行的先后顺序,如果数字相同,则按照先后顺序执行,如果为 null,则代表是结果集,不需要查询。
select_type
分为 simple(简单查询)、subquery(子查询)、drived(衍生表,from 列表中有子查询)、union(联合查询)等。
table
通常是表名,或者表的别名,或者一个为查询产生临时表的标示符(如派生表、子查询、集合)。
type
扫描类型(性能从高到低):
null:MySQL在优化过程中分解语句,不需要访问索引或表就可以得到结果。
system:表中只有一行数据或者该表为空表,这个方式通常出现在 myisam 和 memory 的引擎中,innodb 一般会展示为 all 或 index。
const:使用唯一索引或者主键,返回记录一定是 1 行记录的等值 where 条件时。
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量
eq_ref:出现在要连接几个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为 not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现 eq_ref。唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现。常见于辅助索引的等值查找;多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
range:以范围的形式扫描数据,对索引的扫描开始于某一点,返回匹配值域的行,常见于使用
>,<,is null,between,in,like等运算符的查询中。index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所有索引,性能可能大部分时间都不如range
index:索引全表扫描(Full Index Scan),把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。index 与 ALL 区别为 index 类型只遍历索引树。
all:这个就是全表扫描数据文件(Full Table Scan),然后再在 server 层进行过滤返回符合要求的记录。
range、index、all 需要添加合适的索引。
possible_keys
本次查询可能会用到的索引
key
实际使用到的索引。
key_len
键长
ref
使用的索引列用的查找方式:
const:使用常数等值进行查询。
func:使用了表达式或函数。
rows
预估需要扫描的行数,其中如果行数到达表总行数一定的比例的时候,就会不使用索引。
filtered
通过过滤条件之后对比总数的百分比。
给出了一个百分比的值,这个百分比值和rows列的值一起使用,可以估计出那些将要和执行计划中的前一个表(前一个表就是指id列的值比当前表的id小的表)进行连接的行的数目。
Extra
using index
本次查询使用了覆盖索引,直接通过索引就可以返回结果,无需进行回表。
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
For InnoDB tables that have a user-defined clustered index, that index can be used even when Using index is absent from the Extra column. This is the case if type is index and key is PRIMARY.
从表中仅使用索引树中的信息就能获取查询语句的列的信息, 而不必进行其他额外查找(seek)去读取实际的行记录。当查询的列是单个索引的部分的列时, 可以使用此策略。对于具有用户定义的聚集索引的 InnoDB 表, 即使从Extra列中没有使用索引, 也可以使用该索引。如果 type 是 index 并且 Key 是主键, 则会出现这种情况(并非只有这一种情况)。
using where
A WHERE clause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if the Extra value is not Using where and the table join type is ALL or index.
Using where has no direct counterpart in JSON-formatted output; the attached_condition property contains any WHERE condition used.
where 子句用于限制与下一个表匹配的行记录或发送到客户端的行记录。除非您特意打算从表中提取或检查所有行,否则如果 Extra 值不是Using where 并且表连接类型为 ALL 或 index,则查询可能会出错。
MySQL 服务器在存储引擎收到记录后进行后过滤(Post-filter),先读取整行数据,再判断是否符合条件,符合保留,不符合丢弃。如果查询未能使用索引,Using where 的作用只是提醒我们 MySQL 将用 where 子句来过滤结果集。这个一般发生在 MySQL 服务器,而不是存储引擎层。一般发生在不能走索引扫描的情况下或者走索引扫描,但是有些查询条件不在索引当中的情况下。
using index condition
Tables are read by accessing index tuples and testing them first to determine whether to read full table rows. In this way, index information is used to defer (“push down”) reading full table rows unless it is necessary. See Section 8.2.1.5, “Index Condition Pushdown Optimization”.
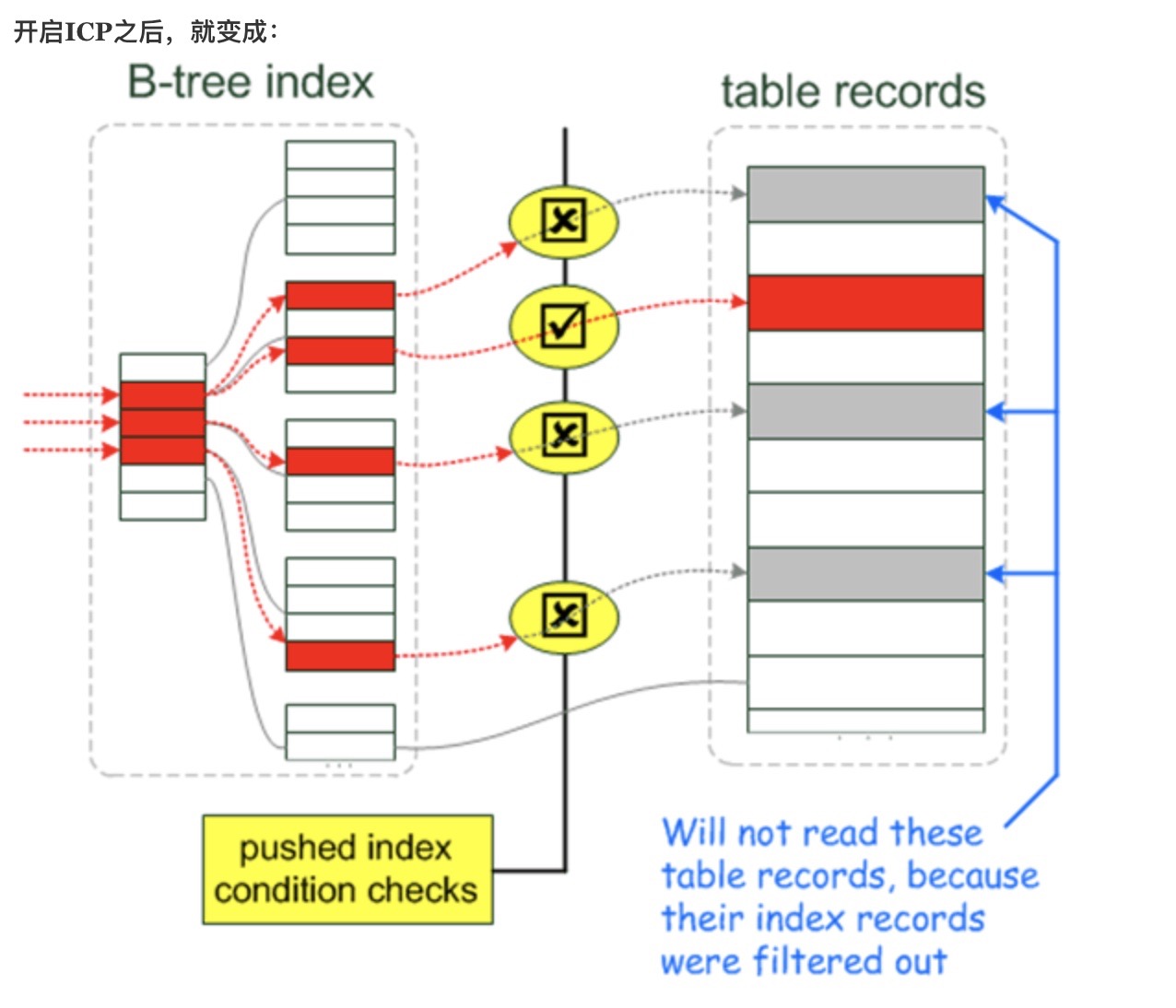
mysql 5.6 时出现的新特性,基于 ICP(Index Condition Pushdown),即如果你的查询条件里有部分可以走索引,那么则会先将条件推到底层的存储引擎层去做一部分过滤,找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行,以此减少查询的条数。因此基于 icp 的概念,在我们使用组合索引的场景不是很明确时,最好可以分别建立索引。
using filesort
当需要的排序和使用索引的排序不一致时,即无法通过索引排序,在获取结果之后,还需要对结果进行再一次的排序。
MySQL 中无法利用索引完成的排序操作称为“文件排序”。
当我们试图对一个没有索引的字段进行排序时,就是filesoft。它跟文件没有任何关系,实际上是内部的一个快速排序。
Using where; Using index 和 Using index condition
Using index condition : where condition contains indexed and non-indexed column and the optimizer will first resolve the indexed column and will look for the rows in the table for the other condition (index push down)
Using where; Using index : ‘Using index’ meaning not doing the scan of entire table. ‘Using where’ may still do the table scan on non-indexed column but it will use if there is any indexed column in the where condition first more like using index condition
Which is better?
Using where; Using indexwould be better thenUsing index conditionif query has index all covering.When ‘Column Extra’ says
Using Index Condition, all columns in where condition are using index. If there are any columns out of index, then Column Extra sayUsing Where; Using Index(in this case, Mysql need look for in data row to apply where clause). It’s betterUsing Index Condition.
ICP
在没有 ICP 之前,存储引擎根据索引去基表查找,然后将数据返回给 mysql server,mysql server 再根据 where 条件进行过滤。
ICP 是在取出索引的同时,判断是否可以根据索引当中的列进行 where 条件过滤,将 where 条件的过滤放在了存储引擎。
ICP 的执行步骤是:
在存储引擎获取一条索引基础数据。
存储引擎根据上面的数据,结合where条件,判断是否满足where条件,如果没有满足条件,回到第一步,筛选下一条数据,否则的话,进行下面的判断。
对于满足下推条件的数据,存储引擎根据 B+ 树的 key,定位基表的行数据,并返回整行数据至 server 层。
在 server 层筛选没有被下推到存储引擎层 where 条件,满足则使用,否则丢弃。
二、优化经验
- 要对经常进行搜索,排序,分组的列创建索引。
- 考虑列基数(同一个列中的不重复的值的数量),列基数越大,效果越好,即区分度越高。
- 索引的数据类型尽可能的短,如果tinyint可以实现,就不要用Int
- 使用最左前缀。
- 不要建立过多的索引。
- insert的时候可以考虑使用批量插入。
- like的时候不要在初始位置使用通配符。
Extra列
出现以下情况时,考虑优化:
using filesort 使用外部排序,而不是按照索引顺序排序,数据量少时通过内存排序,否则需要通过磁盘排序(需要添加合适的索引)
using temporary 创建一个临时表来存储数据,一般出现在对非索引的列集进行 group by 时 (需要添加合适的索引)
using where 通常是对全表/全索引进行扫描之后,再用 where 条件进行筛选查询出来的,通常 type 列为 all 或者 index.(需要添加合适的索引)
using index 表示当前的查询条件都能够从索引树当中获取,不需要进行回表查询,即(索引覆盖)说明性能还可以,需要和type列当中的 index 进行区分。如果同时出现了 using where 表明进行了索引被用来执行键值的查询,如果没有using where表明索引用来读取数据,而非查找,以上两种情况都是从 mysql 服务层完成的,无需再回表查询记录。
索引操作
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
1.ALTER TABLE
ALTER TABLE 用来创建普通索引、UNIQUE 索引或 PRIMARY KEY 索引:
1 | |
其中 table_name 是要增加索引的表名,column_list 指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名 index_name 可选,缺省时,MySQL 将根据第一个索引列赋一个名称。另外,ALTER TABLE 允许在单个语句中更改多个表,因此可以在同时创建多个索引。
2.CREATE INDEX
CREATE INDEX 可对表增加普通索引或 UNIQUE 索引:
1 | |
table_name、index_name 和 column_list 具有与 ALTER TABLE 语句中相同的含义,索引名不可选。另外,不能用 CREATE INDEX 语句创建 PRIMARY KEY 索引。
3.索引类型
在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为 PRIMARY KEY 或 UNIQUE 索引。对于单列惟一性索引,这保证单列不包含重复的值。对于多列惟一性索引,保证多个值的组合不重复。
PRIMARY KEY 索引和 UNIQUE 索引非常类似。事实上,PRIMARY KEY 索引仅是一个具有名称 PRIMARY 的 UNIQUE 索引。这表示一个表只能包含一个 PRIMARY KEY,因为一个表中不可能具有两个同名的索引。
下面的SQL语句对 students 表在 sid 上添加 PRIMARY KEY 索引:
1 | |
4.删除索引
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下:
1 | |
其中,前两条语句是等价的,删除掉table_name中的索引index_name。
第3条语句只在删除 PRIMARY KEY 索引时使用,因为一个表只可能有一个 PRIMARY KEY 索引,因此不需要指定索引名。如果没有创建 PRIMARY KEY 索引,但表具有一个或多个 UNIQUE 索引,则 MySQL 将删除第一个 UNIQUE 索引。
如果从表中删除了某列,则索引会受到影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
5.查看索引
1 | |
参考
https://dev.mysql.com/doc/refman/5.7/en/index-extensions.html
https://www.cnblogs.com/kerrycode/p/9909093.html
https://www.cnblogs.com/tianhuilove/archive/2011/09/05/2167795.html
(完)